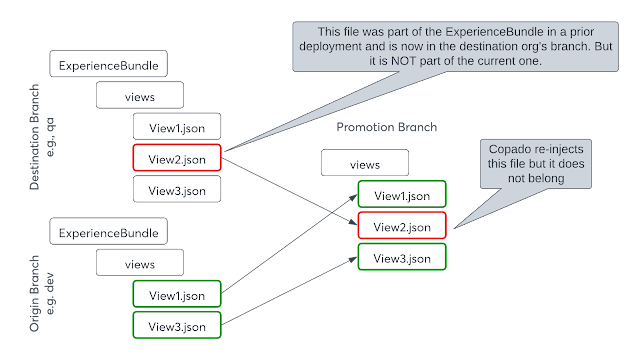
Community Deployments: Duplicate Priority Values
When deploying a Community (Experience Cloud) with Audiences, we sometimes get an error like this: Remove duplicate priority values.Details:Personalization Target Info ID - 6At3C000000HaltSAC,Target Type - ExperienceVariation,Target Value - Home_Theme_Navigation_Menu_3_Component_Properties,Group Name - 3f555c74-248d-4f2c-a8b2-5d27fc4814c0$#$7be51a96-6390-4437-99f0-d1e9072649a7,Publish Status - Draft,Group Priority - 9 What's going on here is that the priorities you set in your Audiences are stored across the Audience files. You'll see in the Audience that there are multiple target nodes: <target> <groupName>ecdea109-1ddb-4b66-9452-ebc43120220b$#$7dce6e95-ba15-4481-bb64-e6fd08f79488</groupName> <priority>1</priority> <targetType>ExperienceVariation</targetType> <targetValue>2023_Home_English_Section_Component</targetValue> </target> The short answer to th